
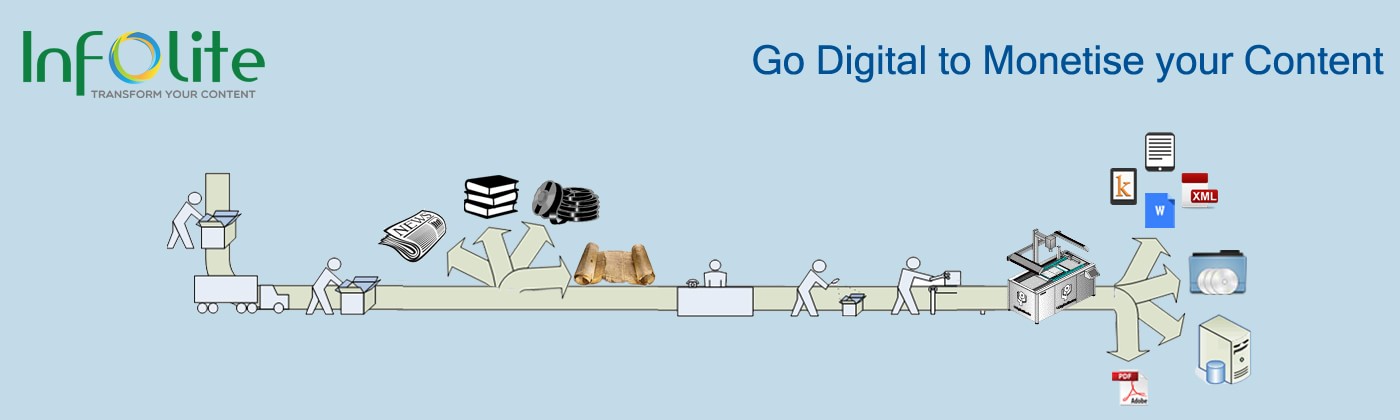










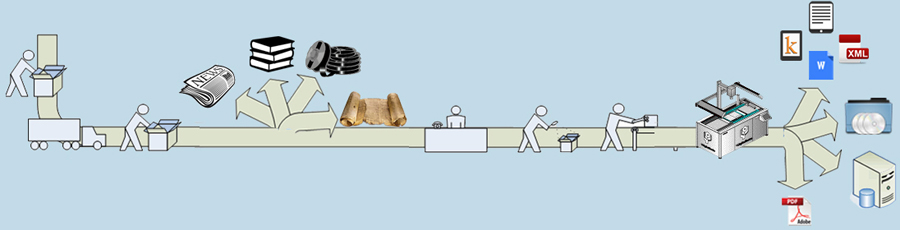
Digitization
Infolite’s Digitization and data capture service offers clients a complete, cost-effective paper-to-electronic solution. We have delivered speedy, seamless, and high-quality data digitization services to organizations across various industries, enabling them to extract and convert data from any source—digital, typed, or handwritten. We leverage state-of-the-art Laserfiche Enterprise Content Management software suite and the technical expertise of our specialists to offer the entire gamut of scanning & digitization and value-added services.
Our service specializes in document capture/Imaging of documents, bound volumes of books/journals including rare and fragile items and newspapers (hard copy and microfiche/film ) into searchable indexed digital assets resulting in improved access to your organization's collection while providing a digital image ideal for archival storage. Our operators are trained in material handling and preservation techniques ensuring that each valuable collection is returned in the same condition in which it was received. We use non destructive scanning methods to scan bound books thereby preserving the condition of your book.
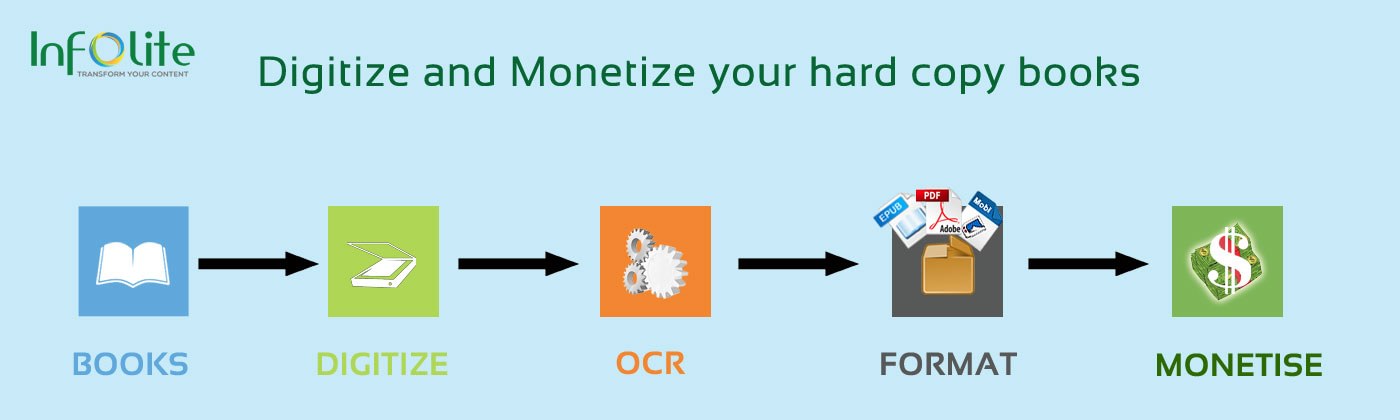
Our digitization process
Non destructive Book scanning
Some books and documents are fragile or too valuable to be scanned using traditional flatbed scanning technology. In such cases we use overhead scanning technology that provides quality digitised output whilst preserving the original condition of the book.This technology allows rare or fragile books to be handled sensitively minimising any damage to covers, pages, spines and bindings, which are often damaged using other scanning technology. Our technology allows high resolution capture of otherwise un scannable books for online use or for re-printing purposes.
General Book and newspaper Scanning
If the books you wish to scan are not rare our team can offer a cost effective scanning solution via our Flatbed scanning technology. The Flatbed technology allows for fast, cost effective digitization of wide ranging books to a high resolution for use online or for re-production purposes. Once your books have been scanned we can use OCR technology to make your books searchable, which is particularly useful if your book will be used online. Additionally once your content have been scanned our in-house team of experts will re-touch each page and image to ensure that the output is as high quality, if not better than the original copies. At Infolite we handle large libraries of books as well as smaller volumes of books, so whatever your scanning requirements, we have a solution to help. Our book and news paper digitizing team are happy to advise with regard to the most cost effective and appropriate technique to scan your books to ensure that the output is in accordance with your needs.
Digitization services
Image capturing using Non destructive scanning
- Data capture across all sizes from A5 to A0
- Newspapers , Manuscripts , Journals and Maps
- Usage of over head scanners and flat bed
- Digitise in color,greyscale or black and white
- Scan range from 200 to 800 dpi
- Advanced image processing and enhancement
- Quality assurance process
- Optical Character Recognition (OCR)
- Conversion to PDF and other formats
- Copies of raw images (JPEG) and final output (PDF)
Optimize Your Resource Usage
Even with a document management system, data entry and filing can still be expensive. Manually sorting paper and electronic documents for processing, then applying metadata and creating folder structures to file them in, can often require full-time staff dedicated to electronic data entry and filing.
Laserfiche Quick Fields transforms capture and indexing into an efficient process, helping you reclaim time and money for other important activities.
Designed for high-volume environments, Laserfiche Quick Fields' production-level tools automatically capture precise pieces of information from paper and electronic documents, turning unstructured information into a viable, actionable resources. By improving the speed and accuracy of repetitive manual processes, Laserfiche Quick Fields also helps you conserve staff time and IT resources.
The Laserfiche Quick Fields Process
Capture
Capture Documents From:
- Laserfiche repositories
- ISIS, TWAIN, Kofax or specialized scanners
- Network folders
- Fax servers
Pull the information you need from paper and electronic documents, faxes, forms and third-party databases and applications, eliminating information silos.
Identify
Identify and Classify Documents Using:
- Image data
- Barcodes
- Data from a third-party database
- Document contents
- Page size
Categorize and index documents without labor-intensive pre-sorting.
Process
Process Captured Images:
- Image enhancement
- Image modification or deletion
- Data extraction and validation
- Annotations/stamps
Use extracted information to fill in fields, apply stamps or annotations, or automatically create folder structures and file documents.
Review
Review:
- Image quality
- Document content
- Document name
- Storage location
- Field data
- Tags
Store
Store Processed Documents in Laserfiche:
- Store immediately or schedule a time
- Perform resource-intensive processes on storage
Capture the Power Of Your Information
Add documents from both paper and electronic sources into your repository with capture tools designed to simplify repetitive processes. From automatically cleaning up scanned images for improved text and data extraction to automatically correcting scanning errors, Laserfiche Quick Fields provides the functionality you need to capture information faster—and more accurately.
- Read text from electronic documents to quickly sort documents and extract information to fill out fields and create folder paths.
- Capture and process documents in a variety of electronic formats, including PDFs and Microsoft Word documents.
- Adjust to changing business conditions by reprocessing documents already in your Laserfiche repository.
- Schedule automated processing sessions around the clock, without requiring operator intervention.
Laserfiche Quick Fields in Action
Bloss & Dillard Inc. used Laserfiche Quick Fields to dramatically reduce the costs of scanning 350,000 documents into their Laserfiche system. Automation with Laserfiche Quick Fields saved 20 minutes per policy and resulted in over $23,000 in saved labor costs. And since implementing Laserfiche, the firm has cut the amount of time necessary to issue a new policy from 10 days to three.
Identify and Classify Documents Without Manual Processing
Manual sorting isn’t just time-consuming and error-prone—it’s also expensive. Laserfiche Quick Fields automatically identifies and sorts documents, enabling you to customize handling, processing and information-capture for specific document types. Whether you recognize forms or documents based on page format or size, document contents or other characteristics, you eliminate the need for manual sorting and processing.
With Laserfiche Quick Fields, you can easily manage multiple document classes in a single processing session, optimizing resources and improving processing speed. Classify documents using barcodes, fields, form identification or any characteristics that fit your organization’s needs—Laserfiche Quick Fields automatically pulls the information you need from large batches of unsorted documents, preventing costly errors and operational bottlenecks. You save time and resources, enabling staff to spend time on more productive tasks.
- Automatically identify and sort forms, customize information capture for specific forms and optimize the quality of scanned images.
- Use document characteristics, contents or size to identify whether a page is the beginning of a new document.
- Use iFilter technology to recognize the text associated with electronic documents.
- Assign document types on the fly, improving quality assurance and eliminating reprocessing.
Identify and Classify Documents Without Manual Processing
Unprocessed Form
Processed Form
-
1
Page Size Identification
Identify document types based on page format or size.
-
3
Zone OCR
Recognize document types based on text extracted from designated areas of a document.
-
4
OMR / Auto-OMR
Optical Mark Recognition (OMR) detects checkmarks on surveys, tests and ballots. Auto-OMR automatically detects multiple zones for validation.
-
5
Form Extractor
Remove form outlines, isolating data for more accurate capture.
-
6
Form Alignment
Automatically reposition the document to match a master form, correcting for scanning errors and improving data extraction.
Form Identification
Recognize a document based on its overall characteristics—even without distinguishing information such as barcodes.
Text and Token Identification
Use document contents—including words and word patterns—to identify documents that require processing.
Document Classification
Eliminate the need for manual sorting by automatically classifying multiple document types in a single processing session. Documents can be classified using barcodes, fields, Form Identification and a variety of other methods.
Token Retriever and Collector
Manage multiple document classes in a single processing session using information extracted from barcodes, fields, header sheets or other methods.
Categorize and Organize Unstructured Data
Once you’ve sorted and identified your documents, Laserfiche Quick Fields enables you to automate the processes required to get the most value from the information you’ve collected. Laserfiche Quick Fields extracts the precise pieces of information you need from paper forms, electronic documents and databases, then uses that information to categorize and organize unstructured data. You increase your operating speed and effectiveness while reducing the time spent transferring information between applications.
- Improve the accuracy of newly captured information by comparing it with data from other applications.
- Use extracted data from barcodes, document content and customizable areas of forms to automatically name, index and assign metadata to documents, kick start a Workflow process or interact with a Workflow already in process.
- Support all Laserfiche 8 field types, including multi-value fields and fields independent from templates.
- Conserve network bandwidth by automatically transferring processed docmuents to the Laserfiche repository at scheduled intervals.
“It just takes seconds for our front counter clerks to create batch header sheets with barcodes, and Quick Fields does the rest.”
Garth Bambling / Front Counter Supervisor / York County Clerk of Courts Office, PA
Quick Fields in Action
The York County, PA, Clerk of Courts Office uses Laserfiche to manage over 8,000 cases processed annually. Staff create barcoded batch header sheets, but Quick Fields does the heavy lifting.
Categorize and Organize Unstructured Data
-
2
Zone OCR
Populate fields, create document names and make indexing decisions based on text extracted from designated areas of a document.
-
3
Pattern Matching
Use regular expressions to separate, verify and correct specific phrases from larger blocks of text captured by Zone OCR.
-
4
Real-Time Lookup
Extract and validate metadata by retrieving information from databases and third-party applications.
Text-to-Token Conversion
Extract text from your documents and transform them into tokens for use in document indexing and naming.
Field and Token Verification
Validate extracted data by comparing it to a database, completely eliminating manual input and review.
Bates Numbering
Automatically apply unique identifiers for evidentiary documents.
Permanent Stamps
Permanently affix stamped text or images to processed documents.
Automatic and Fixed Annotations
Automatically apply annotations—including highlight, personal stamp, sticky note and redaction—to specified regions of a document.
Functionality
Image Processing |
|
Image Enhancement |
|
Data Extraction and Storage |
|
Environment
Operating Systems |
|
Protocols |
|
Authentication |
|
Virtualization |
|
Infolite Digitization services
- Book/Hardcopy scanning, data capture and indexing
- Automated Identification and Classification
- Scanned Image processing & enhancement
- Optical character recognition / Intelligent character recognition
- OMR and Barcode
- Automated Forms capture
- Customized MIS and reporting
- Cloud based document management software
Key business benefits
- Future proofing: capture a high quality image only once
- Various output options (PDF, XML, MS Word etc)
- Alternate formatting & editing services
- Covert your books to ebook formats such as ePub and Kindle MOBI
- Archive your information sources with secure backup
- Quality output with a high level of accuracy and a wide choice of image formats
- Automate content oriented processes
- Adherence to critical TAT requirements and SLAs, with streamlined processes
- Assured data privacy, high level of data security, and expert in-house IT support
- Faster TAT; dramatic reduction in OpEx; and cost-efficient, scalable solutions
- Effective preservation, quick retrieval and access, easy storage, and effortless duplication of data
- Incisive insights via real-time MIS and reporting capabilities
The Infolite advantage
- Infolite’s Scanning & Digitization services offer the best in terms of resources, processes, and people:
- Platform-based services and integrated workflow solution for managing end-to-end processes, leading to a lower Total Cost of Ownership
- State-of-the-art document scanning methodology
- A resource pool with deep domain knowledge and expertise
- Cost-effective Imaging business solutions
- Round-the-clock customer support
- Enhanced business intelligence systems with real-time MIS/reporting dashboards
- Proven scalability and a track record of delivering sustained value, consistently
|
Contact us on our email : reachus@infolitetech.com
|